
What Are Large Language Models?
A Large Language Model (LLM) is a deep learning algorithm trained on massive datasets to read, summarise, translate, predict, and generate content. Built on the transformer architecture, LLMs are the cognitive engine behind modern AI, powering everything from simple chatbots to complex Agentic AI systems.
Early models were just pattern recognition engines, modern LLMs are foundation models. They have a deep understanding of human language and logic and can solve problems across software engineering, healthcare, and creative arts.
From Generative to Agentic AI
The most significant advancement in LLMs is the shift to Agentic AI. While Generative AI creates content (text or images) based on prompts, Agentic AI uses the LLM as a “brain” to do things. These systems can reason, plan, and autonomously execute multi-step workflows – like booking a flight or debugging software – with minimal human intervention.
What Can LLMs Do? (Key Capabilities)
Large Language Models are versatile foundation models that can be fine-tuned for a vast range of tasks. By processing billions of parameters, they understand the semantic relationships between words, allowing them to manipulate and create text with human-like fluency. Here are the primary capabilities of LLMs:
1. Text Generation (NLG)
Natural Language Generation (NLG) is the ability to produce coherent, contextually relevant, and original content. LLMs predict the most statistically probable next token (word) in a sequence to draft content ranging from technical documentation to creative storytelling.
- Example: A marketing team provides a prompt like, “Write three engaging Facebook ad headlines for our new eco-friendly water bottle,” and the LLM generates creative, ready-to-launch options in seconds.
2. Agentic Reasoning & Task Execution
Beyond simple text generation, LLMs now power autonomous agents. These agents can break down complex goals into smaller sub-tasks, use external tools (like web browsers or APIs), and execute actions to achieve a specific outcome.
- Example: Instead of just writing an email, a system of AI agents can read your calendar, identify a conflict, draft a rescheduling email, and send it to the client—all without you clicking a button.
3. Question Answering & Information Synthesis
Unlike traditional search engines that provide a list of blue links, LLMs synthesize information from their training data to provide direct, conversational answers. They act as reasoning engines that consolidate complex topics into easy-to-digest summaries.
- Example: Asking, “What were the main socioeconomic causes of the Industrial Revolution?” yields a concise paragraph explaining the key factors, rather than requiring you to read five different articles.
4. Text Summarization
LLMs excel at extracting the “signal” from the “noise.” They can analyze large volumes of unstructured text, such as academic papers or legal contracts, and distill them into their essential points, significantly boosting productivity.
- Example: A financial analyst uploads a 50-page earnings report and asks the LLM to generate a one-page executive summary highlighting key financial metrics and management outlooks.
5. Language Translation
Modern LLMs utilize deep semantic understanding to provide translations that capture cultural nuances, idioms, and tone, far surpassing literal word-for-word conversion tools.
- Example: An LLM can accurately translate the English idiom “it’s raining cats and dogs” into the target language’s cultural equivalent for heavy rain, preserving the intent rather than just the words.
6. Conversational AI
This technology powers the next generation of conversational AI platforms. By utilizing a large context window, LLMs remember previous turns in a conversation, allowing for natural, free-flowing dialogue that maintains context over time.
- Example: A customer service bot handles a query like, “My first order was damaged, can I get a replacement?” by recalling the specific order details discussed minutes earlier, without asking the user to repeat themselves.
7. Code Generation and Debugging
For developers, LLMs act as intelligent pair programmers. They can generate functional code snippets from plain English descriptions, translate code between languages (e.g., Java to Python), and explain complex logic for debugging purposes.
- Example: A developer prompts, “Create a Python function that takes a CSV file and calculates the average of the ‘sales’ column,” and the LLM outputs clean, executable code.
8. Sentiment Analysis
LLMs can process text to determine emotional tone, positive, negative, or neutral. This allows businesses to gauge public opinion at scale by analyzing unstructured data like product reviews and social media comments.
- Example: A brand scans thousands of Twitter mentions after a product launch to automatically categorize sentiment and identify specific pain points consumers are discussing.
Examples of Popular Large Language Models
While the technology is complex, several key LLMs have become household names and are driving the generative AI revolution:
- GPT Series (OpenAI): The Generative Pre-trained Transformer models, especially GPT-3.5 and GPT-4, are famous for powering ChatGPT and are known for their strong conversational and content creation abilities.
- Gemini (Google): Google’s flagship model, Gemini, is natively multimodal, designed from the ground up to understand and reason across text, images, code, and video.
- Claude (Anthropic): Developed with a strong focus on AI safety and ethics, Claude is known for its large context window, allowing it to process and analyze very long documents.
- LLaMA (Meta AI): Llama (Large Language Model Meta AI) is a family of open-weight models released by Meta to help spur research and development in the AI community. for examples LLaMa 4 is popular multimodal LLM.
How Do Large Language Models Work?
Large Language Models (LLMs) leverage sophisticated natural language processing (NLP) and machine learning techniques to understand and generate language. A critical component is the self-attention mechanism of the Transformer architecture, which allows the model to focus on different parts of the text simultaneously, understanding contextual relationships between words.
NLP enhances this process with LLM embeddings, enabling models to capture the overall meaning of the text, which is crucial for generating coherent responses. In the language generation phase, an initial prompt is processed by foundation models that use a combination of self-attention and decoder algorithms in the Transformer to generate a sequence of tokens. These tokens are then refined for contextual relevance through advanced NLP techniques and assembled into a coherent response.
The Training Process: From Data to Knowledge
Training is how an LLM develops its ability to read, write, and reason. It’s a multi-stage journey that turns raw text into a sophisticated neural network.
1. Data Collection and Preprocessing: The process begins by gathering a massive dataset, often hundreds of billions of words from the public internet, books, articles, and other sources. This raw data is then cleaned and preprocessed to remove formatting errors and irrelevant content, preparing it for the model.
2. Pre-training (Unsupervised Learning): This is the main learning phase. The model is shown the vast dataset and given a simple but powerful task: predict the next word in a sentence or fill in missing words. By doing this billions of times, it begins to learn grammar, facts about the world, common sense reasoning, and the subtle relationships between concepts—all without explicit human instruction.
3. Fine-Tuning (Supervised Learning): After pre-training, the general model is refined for specific tasks. During fine-tuning, developers train the model on a smaller, high-quality dataset of curated examples. This stage often involves techniques like Reinforcement Learning from Human Feedback (RLHF), where human reviewers rate the model’s responses, teaching it to be more helpful, accurate, and aligned with human values.

The Core Engine: The Transformer Architecture
Modern LLMs owe their success to a breakthrough neural network design called the Transformer architecture, introduced in 2017. Unlike older models that processed text word-by-word, the transformer models can process entire sequences at once, giving it a much deeper understanding of context.
Here are its key components:
- Tokenization: Before the model can “read” text, the sentences are broken down into smaller pieces called tokens. Tokens can be words, parts of words, or even individual characters. For example, the sentence “LLMs are powerful” might become the tokens [“LLMs”, “are”, “power”, “ful”].
- Embeddings: Each token is then converted into a numerical representation called an embedding—a vector of numbers. LLM embeddings are crucial because they capture the token’s semantic meaning. In this “vector space,” tokens with similar meanings are located closer to each other.
- The Self-Attention Mechanism: This is the Transformer’s secret sauce. The self-attention mechanism allows the model to weigh the importance of every other token in the input when processing a specific token. It helps the model understand relationships and context, no matter how far apart words are in a sentence. For example, in the sentence, “The robot picked up the ball because it was light,” self-attention helps the model determine that “it” refers to the “ball” and not the “robot.” This ability to grasp long-range dependencies is what makes LLMs so coherent and context-aware.
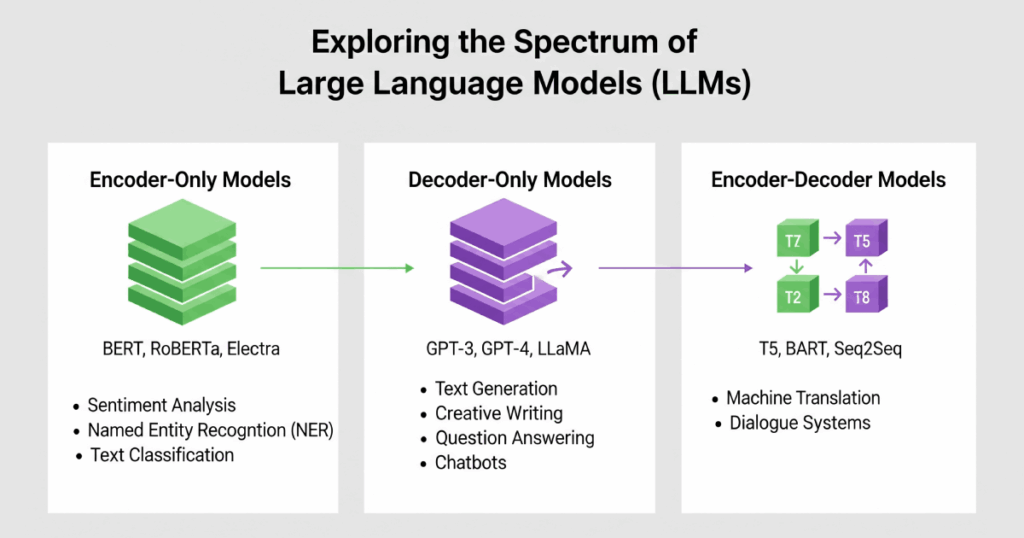
Examples of Large Language Models
Large language models have a wide range of applications across various industries, from large language models in healthcare to natural language processing, content creation, and customer support. In this section, we will explore some of the most notable use cases for LLMs.
- LLMs in Chatbots and Customer Service: Large language models are the engines behind the next generation of intelligent chatbots and AI-powered customer service platforms. Instead of relying on rigid scripts, these models can understand the nuances of customer inquiries and provide natural, conversational responses. They can handle complex, multi-step problems, access knowledge bases to provide accurate information, and even detect customer sentiment to escalate issues when necessary, leading to a more efficient and personalized support experience.
- LLM for Content Creation: A Large language model can be leveraged to generate high-quality text content, including articles, product descriptions, and marketing copy. These models can learn to write in different styles and tones, enabling the creation of unique and engaging content.
- Language Translation: Large language models have the potential to revolutionize language translation by enabling more accurate and nuanced translations of human languages. These models can learn to understand the context of a sentence and generate translations that convey the intended meaning more accurately, improving communication across languages and cultures.
- Other Large Language Models Use Cases: Large language models can also be applied in various other domains, for legal document analysis, customer sentiment analysis in social media, answering questions, and speech recognition. Nowadays, we see the innovative application of LLMs as generative AI in the banking industry or fraud detection by leveraging generative AI in insurance companies. As these models continue to evolve and improve, their applications will only become more widespread and impactful.
Types of Large Language Models
Large language models have a wide range of applications across various industries, from large language models in healthcare to natural language processing, content creation, and customer support. In this section, we will explore some of the most notable use cases for LLMs.
- LLMs in Chatbots and Customer Service: Large language models are increasingly being used to develop intelligent chatbots and AI customer service products to enhance customer experiences. These models can be trained to understand and respond to customer inquiries and even simulate human language conversations, providing more personalized and efficient support.
Leveraging LLMs in customer service often necessitates the use of an LLM Gateway to maximize privacy, security, and efficiency. The gateway ensures that sensitive data is handled responsibly while optimizing the AI’s response quality and relevance. Additionally, it plays a crucial role in maintaining compliance with data protection regulations, thereby enhancing the trust and reliability of AI-driven customer interactions.
- LLM for Content Creation: A Large language model can be leveraged to generate high-quality text content, including articles, product descriptions, and marketing copy. These models can learn to write in different styles and tones, enabling the creation of unique and engaging content.
- Language Translation: Large language models have the potential to revolutionize language translation by enabling more accurate and nuanced translations of human languages. These models can learn to understand the context of a sentence and generate translations that convey the intended meaning more accurately, improving communication across languages and cultures.
- Other Large Language Models Use Cases: Large language models can also be applied in various other domains, for legal document analysis, customer sentiment analysis in social media, answering questions, and speech recognition. Nowadays, we see the innovative application of LLMs as generative AI in the banking industry or fraud detection by leveraging generative AI in insurance companies. As these models continue to evolve and improve, their applications will only become more widespread and impactful.
Limitations and Challenges of LLMs
Despite the many advantages of large language models, several limitations and challenges must be taken into consideration when developing and utilizing such models.
- Biased Output: One major concern with large language models is the risk of bias. These models are trained on large amounts of data, which can include biased content and language. This can lead to perpetuating biases in the language generated by the models. For example, a language model trained on text that contains gender biases, such as associating certain professions mainly with men, may generate biased outputs as well.
- AI Hallucination: AI hallucination refers to situations where a language model generates information that is not just biased or unethical, but outright false or misleading, despite sounding plausible. This can occur even when there’s no direct bias in the input data or intention to deceive. It’s a result of the model’s inherent limitations in understanding and representing knowledge accurately. This phenomenon can complicate the use of LLMs in scenarios where accuracy and truthfulness are crucial, such as in journalism, academic research, or legal contexts.However, leveraging techniques such as RAG and fine-tuning LLMs or even Domain-specific LLMs instead of relying solely on general foundational models can significantly reduce the risk of hallucinations. By tailoring these models to specific domains, they can more accurately reflect relevant facts and contexts, thereby enhancing their reliability and reducing the likelihood of generating incorrect or misleading information.
- Ethical Concerns: The use of a large language model also raises ethical questions. As these models become more advanced, they are increasingly being employed to generate highly convincing fake text, audio, and video. The implications of using such technology for fraud and misinformation are concerning. Additionally, the potential impact on employment and job displacement is another ethical concern that needs to be addressed.
- Computational Requirements: The development and usage of LLMs require significant computational resources. The vast size of the datasets and the extensive number of parameters needed to process the complexity of these models make implementation challenging for many organizations. This often puts smaller entities at a disadvantage, as they may lack the necessary computing power and infrastructure to support large language models.However, small language models (SLMs), which have fewer parameters and are tailored for specific domains and industries, can be more accessible for small organizations. These models can offer a more feasible solution without the overwhelming resource demands of their larger counterparts.
- Robust Evaluation Techniques: Another challenge associated with large language models is the need for robust LLM evaluation techniques. As these models become increasingly sophisticated, it becomes harder to evaluate their performance and accuracy. The development of appropriate evaluation methodologies is crucial to ensure that the outputs of these models are reliable and trustworthy.
- Knowledge Cutoff: Explicitly state that an LLM’s knowledge is frozen at the time of its training and it cannot access real-time information.
- Limited Reasoning Skills: Mention their difficulty with multi-step logic, math, and common-sense reasoning, as they are pattern-matchers, not true thinkers.

The Future of Large Language Models
LLMs have already made a significant impact on the field of artificial intelligence. However, their potential is far from exhausted, and research into further advancements is ongoing.
Advancements in Large Language Models
One direction for future exploration is the development of models with even greater capacity for understanding and generating languages, such as GPT models which have already demonstrated remarkable capabilities. These models open up new possibilities for natural language processing, enterprise chatbots, and AI virtual assistant applications that can communicate seamlessly with humans.
However, alongside popular open-source models like ChatGPT, we are seeing investments in non-English-focused language models around the world, such as IndicBERT in India, which covers 12 major Indian languages.
Another potential development area is the use of large language models in multilingual contexts. Researchers are exploring the creation of models that can effectively translate between multiple languages, facilitating communication across borders and cultures.
Increased Efficiency
As computational power continues to increase, the speed and efficiency of large language models are likely to improve significantly. This advancement will enable the creation of more complex and accurate models. Techniques such as Retrieval-Augmented Generation (RAG) and fine-tuning can make LLMs more efficient and cost-effective, facilitating broader implementation across various industries.
Broader Integration
Large language models are already being utilized in a variety of industries, including customer service, content creation, and language translation. However, their integration is likely to become even more widespread in the coming years, as more businesses recognize the value of AI-powered communication and information processing.
As LLMs become increasingly integrated into various domains, there will be a growing need for skilled professionals who can develop, implement, and manage them effectively. This presents an opportunity for individuals with technical expertise in language processing and artificial intelligence to expand their careers and contribute to the development of this exciting field.
Conclusion
AiseraGPT offers a versatile solution, allowing enterprises to choose their LLM strategy to buy, build, or bring LLMs, and efficiently operationalize them into a chatbot or Generative AI App. Organizations can easily start now and extend seamlessly to any functional domain and/or industry vertical with Aisera’s Enterprise LLM or experience the power of Generative AI and book a custom AI demo today!