Conversational AI Platform
Conversational AI to Build, Train, and Deploy
AI Assistants for the Enterprise
Conversational AI
Conversational AI, powered by Agentic AI reasoning and orchestration, enables enterprise AI assistant software to deliver personalized, human-like interactions with minimal human intervention.
Aisera’s Conversational AI platform helps enterprises build, train, and deploy AI solutions that can understand and process human language across multiple domains and languages, facilitating instant resolution of both customer and employee service requests through effective self-service options.
Best Conversational AI Features
Aisera’s Enterprise Conversational AI Platform features AI Copilot harnesses the power of advanced NLP and Large Language Models (LLMs), incorporating both supervised and unsupervised learning to foster real-time, human-like interactions. This robust combination, trained on vast amounts of textual and speech data, empowers the system to understand and process language dynamically, continuously enhancing its conversational quality.
By leveraging these AI technologies such as AI Customer Service, or AI Service Desk, Aisera not only aims to revolutionize customer and employee experiences but also increases productivity and operational efficiency through automation. This leads to reduced costs, fewer human errors, and elevated customer engagement and satisfaction by providing personalized, 24/7 support across various platforms.
Guided Flows & Bot Orchestration
Give employees, call centers, support teams, and potential customers a prescriptive and proactive conversational experience with AI Copilots offering pre-built supervised guided flows and bot orchestration of top service requests with artificial intelligence while ensuring operational efficiency, enhancing contact center automation, and productivity while providing high auto-resolution rates and elevating both employee and customer satisfaction.
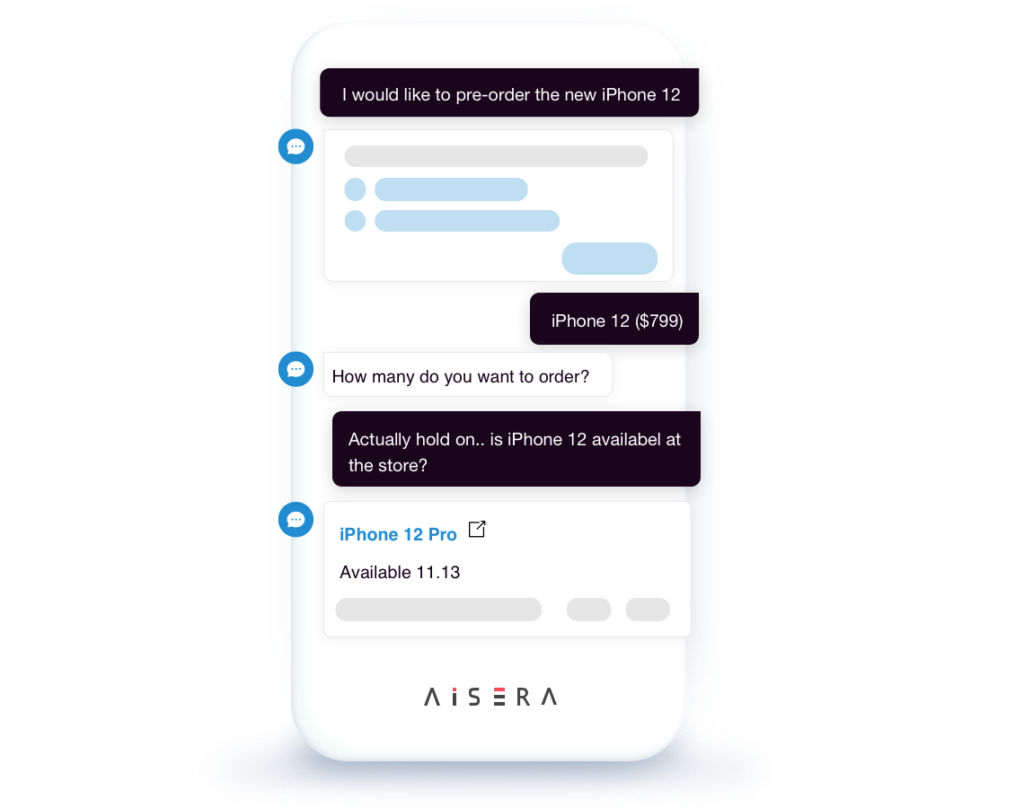
Unsupervised & Supervised Conversational AI
Bootstrap your multilingual IT support and AI assistant with unsupervised & supervised conversational AI that continuously makes sense of structured and unstructured data and automatically understands intents and phrases from analyzing 150 million tickets and over 1.1 billion conversations to delivering self-service resolutions across mobile devices and the omnichannel (AI Voice Bot, Enterprise Chatbots, and text messaging) and in over 100 languages.
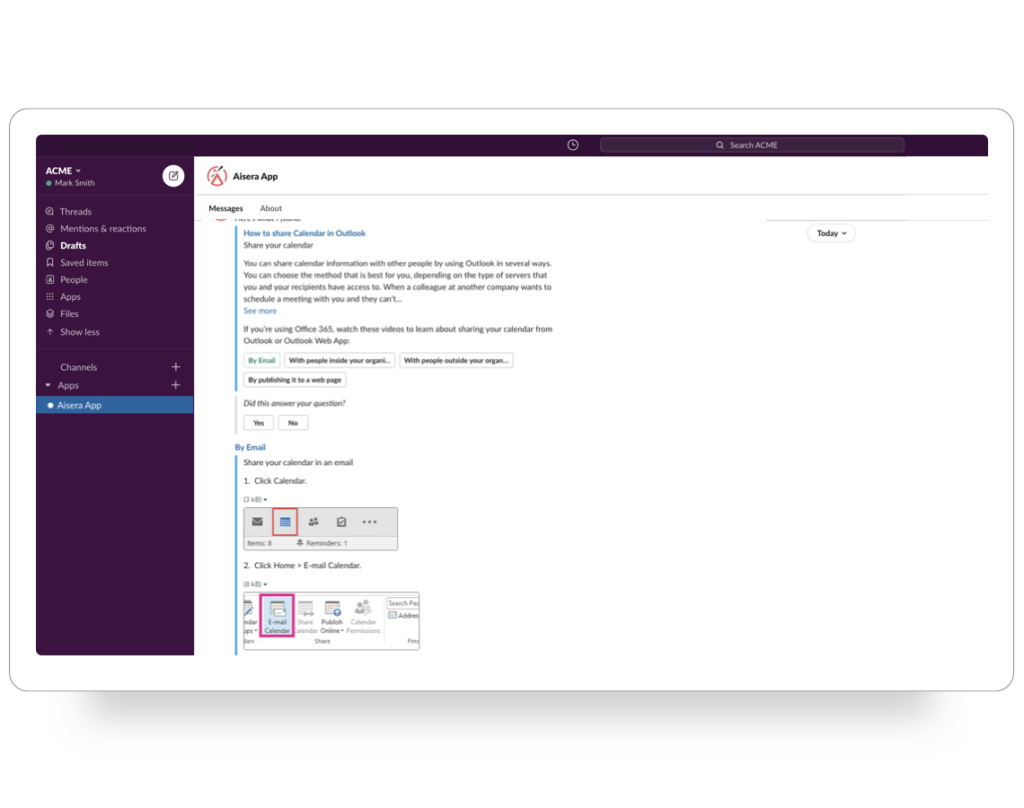
Dialog Management & Context Awareness
Manage user dialogs with Conversational AI that understands the fluidity of conversations, including when users change subjects and dynamically switch contexts midway through conservations without losing track of original requests.
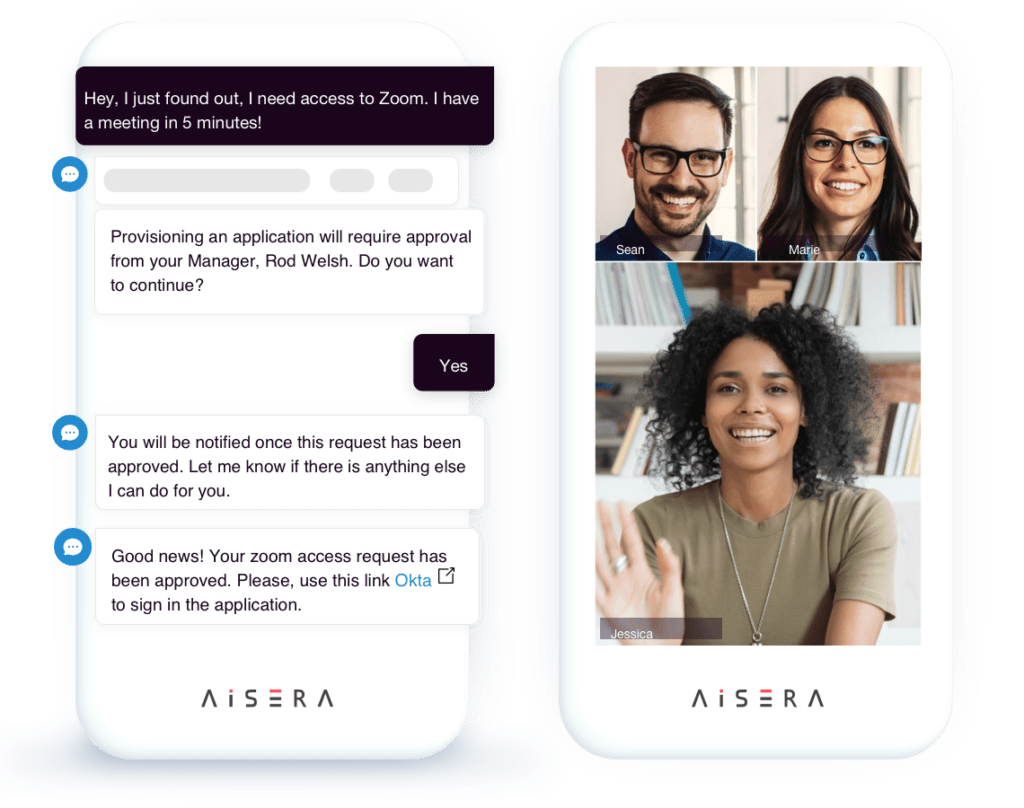
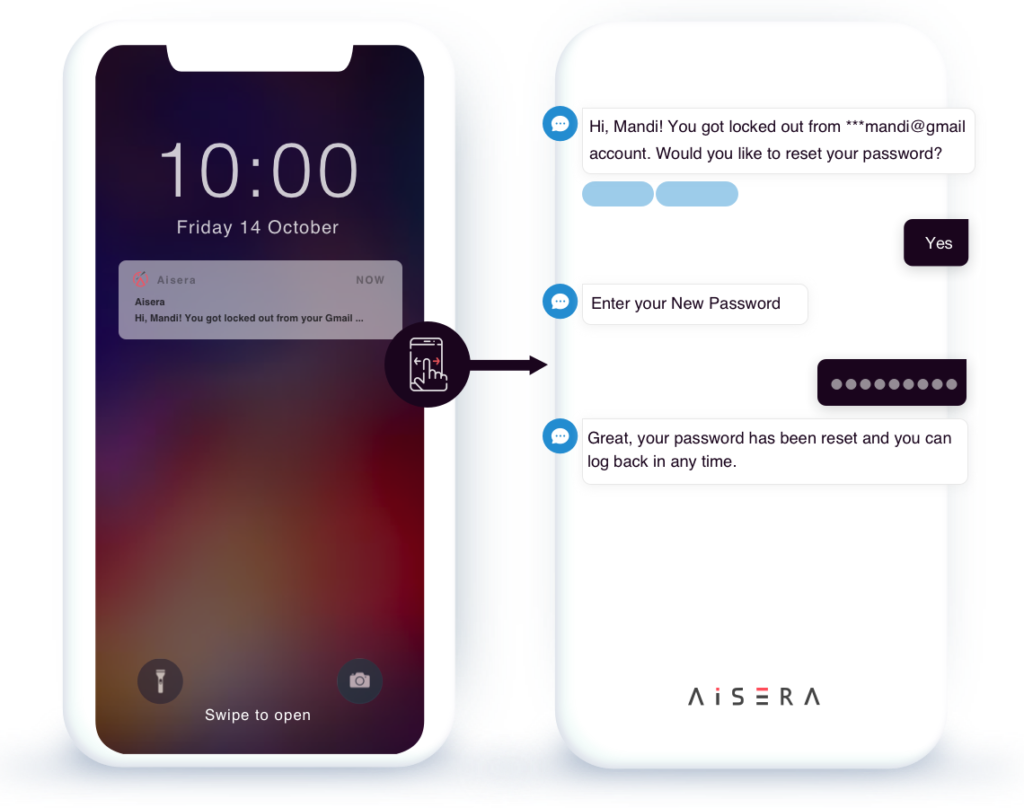
Notifications, User Engagement, & Live Agent Handover
Proactively notify and drive customer engagement by alerting users of tasks that they need to take action on such as routine tasks such as unlocking an account resetting a password or assisting with advanced chatbot and live contact center virtual assistants, for seamless escalation handling.
Interactive Analytics & User Profile-Based Recommendations
Personalize customer experience and service resolutions with the help of a Conversational AI solution. It uses Artificial Intelligence recommendation models, custom dashboards, and in-depth reports that are built on understanding the user’s profile and behavior throughout their online customer support journey.

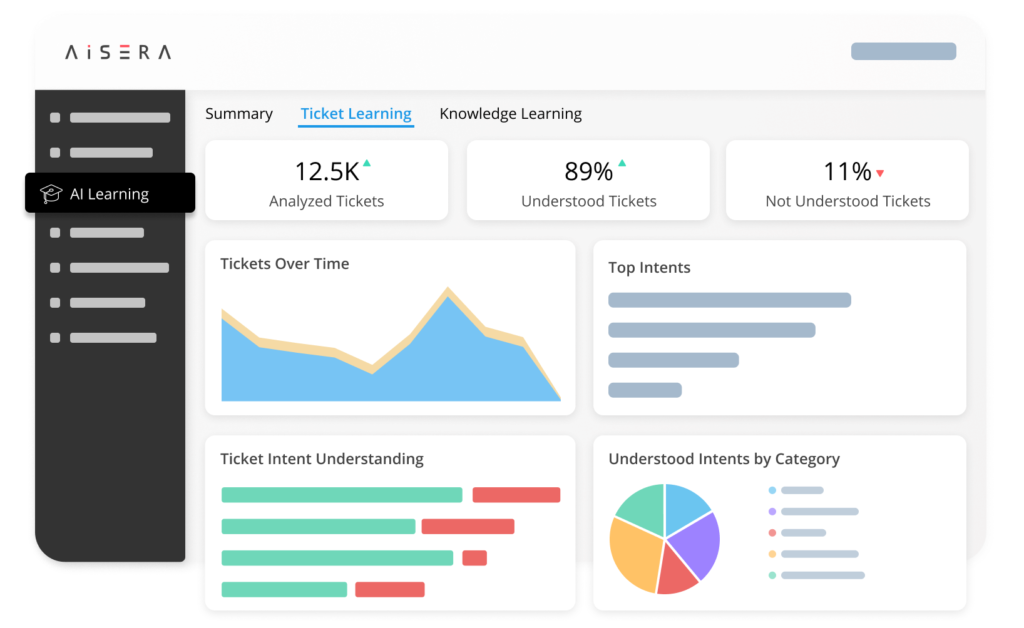
AI Learning
Aisera’s AI-powered bot, functioning as an AI agent for automation, uses automated machine learning, and reinforcement learning using knowledge, past tickets & cases, and live agent conversations as well as life cycle management of intents, utterances, and phrases for better service and continuous improvement of prediction accuracy and response quality for new requests.
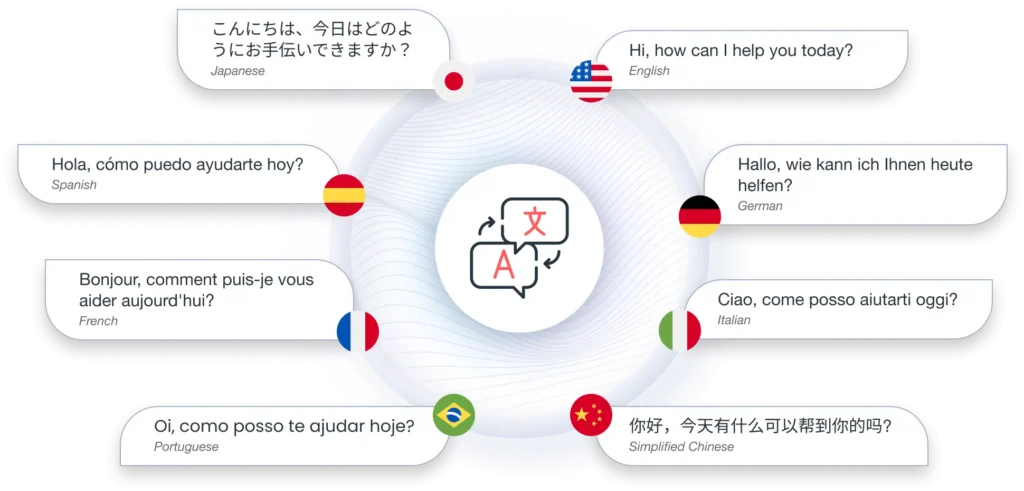
Multilingual Conversational AI
Aisera’s conversational AI platform is multilingual with built-in language detection and quickly responds to over 100 languages available out-of-box. Aisera’s Conversational AI platform with built-in language detection responds to both employee and customer requests in their preferred language and channel of choice.