
What is a Transformer Model?
Transformer models are a type of neural network architecture designed to process sequences of data. They function by applying mathematical techniques called attention mechanisms, particularly self-attention, to detect subtle ways various data (e.g., words in a sentence) relate to and influence each other.
The transformer architecture is a sequence transduction model that relies entirely on self-attention, featuring an encoder-decoder structure and multi-layer stacks for tasks like language translation. These models play a crucial role in processing sequential data, especially in natural language processing, by leveraging self-attention and layered frameworks.
Today, transformer models are used in virtually every advanced AI application: large language models (LLMs), natural language processing (NLP), natural language understanding (NLU), and Agentic AI. As foundation models, transformers serve as the basis for a wide range of AI tasks, driving paradigm shifts in the field due to their scale and versatility.
In this article, we’ll walk through this neural network architecture in detail, highlighting the next-gen capabilities that give companies across industries a competitive edge.
What is a Self-attention Mechanism?
Self-attention mechanisms, the foundational component of transformers, allow models to determine which elements in an input sequence are most relevant to each other, regardless of position. For example, words in a sentence often change their relationship to each other based on placement; the word “her” can modify “her sock” or “her car” depending on its location. The attention mechanism helps disambiguate the same word in different contexts by using surrounding words to clarify meaning.
Transformer models rely on self-attention mechanisms, using multiple attention heads in parallel, to build representations of input and output sequences, eliminating the need for convolution within their architecture. By gaining a deep, contextual understanding of relationships within a given dataset, these models can:
- Understand context by understanding how all data relates to each other, regardless of their distance from one another (like how the first sentence in an article influences the meaning of the conclusion). Attention helps language models resolve ambiguities, especially when the same words appear in different contexts.
- Analyze and compute these relationships simultaneously, which enables the model to handle large datasets faster than if it analyzed them one at a time.
- Weight the importance of each piece of data to determine its importance (like how the subject and verb of a sentence are more important than the or a) to improve its future text generation capabilities.
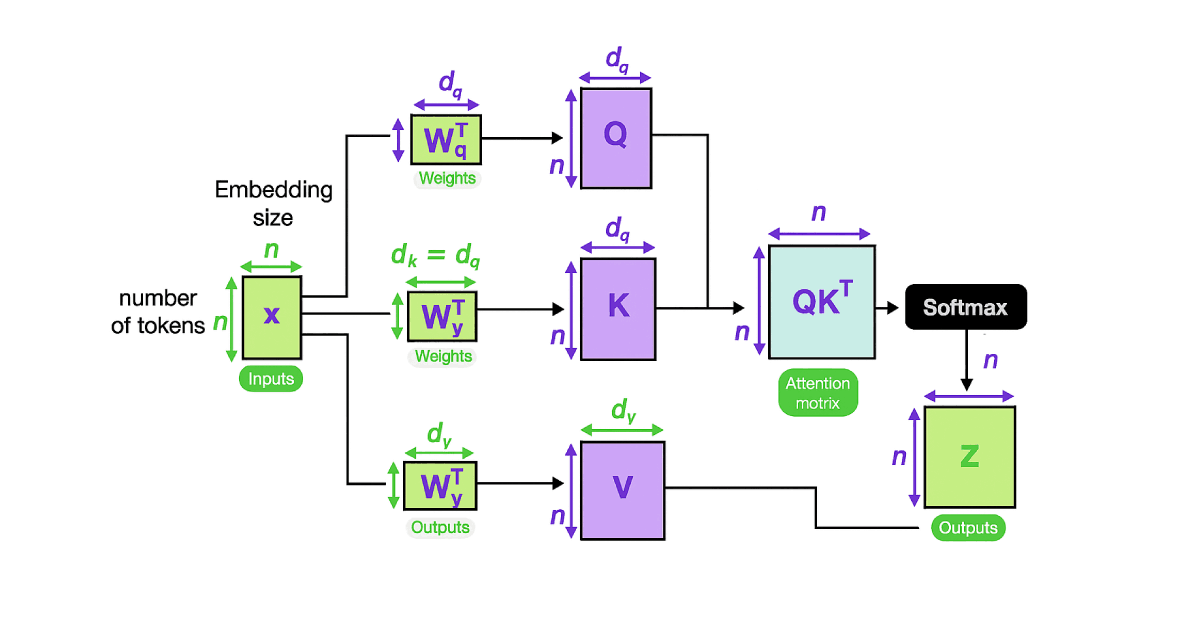
Self-attention works by computing multiple high-dimensional vectors for each element in the sequence. These vectors enable the mechanism to measure the importance of each element in predicting future values in a sequence. Key vectors, along with query and value vectors, are used to calculate attention scores that determine how much focus each word should receive in relation to others.
For example, self-attention mechanisms are used in search engines to determine the most important terms used in a query so they can return the most relevant results. Alternatively, transformer architecture used in domain-specific LLMs (for example, HR) can also prioritize certain terminology that may have a unique meaning within that domain. In HR specifically, if an employee messages a chatbot wanting to “adjust their plan,” that typically refers specifically to a 401(k) or insurance adjustment.
Transformer models with domain-specific knowledge can infer these nuances without the need for follow-up queries or human intervention. Attention is a very useful technique for moving embeddings closer together based on context, rather than embedding simply sends words without context, allowing the model to distinguish between different meanings of the same word.
Transformer Models vs. Neural Network Architectures
The use of a self-attention mechanism distinguishes transformer models from recurrent neural networks (RNNs) and convolutional neural networks (CNNs). Here are some of the other differences among these common neural network architectures.
| Model Type | Description |
| RNNs | These models process data sequentially (step-by-step). They’re excellent for smaller scale tasks, as they require limited resources to implement. However, they have a limited contextual understanding of their environment and no self-attention mechanism. |
| CNNs | These models use convolutional layers, essentially filtering inputs to extract specific information or features. These models work well for image processing, tasks where fast inference and computational efficiency are top priorities, or small language models and medium datasets. They struggle with long sentences, larger datasets, and tasks that require global context. |
| Transformers | These models have a built-in self-attention mechanism, which enables them to process larger datasets. Transformers also operate better when the global context is a priority. However, transformers can also be resource intensive. |
Transformers are considered an evolution of the traditional encoder-decoder architecture used in RNN-based models, but they rely on attention mechanisms instead of recurrence.
What Are the Different Types of Transformer Models?
Although less than a decade old, transformer models have already evolved into a diverse array of deep learning architectures. Here are some of the most prominent ones.
Bidirectional transformers
Bidirectional Encoder Representations from Transformers (BERT) models focus on processing words about all other words in a sentence, rather than in isolation. This model is called “bidirectional” because it accounts for both left-to-right and right-to-left token sequences, allowing for better comprehension. BERT models can be used in internal HR chatbots that understand and respond to complex employee queries.
Generative pre-trained transformers (GPTs)
Thanks to OpenAI’s famous large language model offering, most everyone is familiar with the term “GPT,” but likely don’t know what those letters stand for. Generative pretrained transformers (GPTs) use stacked transformer decoders pretrained on large volumes of text, using autoregressive strategies to predict the next value in a given sequence (e.g., word in a sentence).
Bidirectional and autoregressive transformers
Bidirectional and autoregressive transformers (BART) combine the bidirectional properties of BERT with the autoregressive properties of GPT. This means that it reads the entire sequence at once, but generates the output one token at a time.
Vision transformers
Although traditional transformer models are unable to handle image classification, vision transformers (ViT) can. They do this by converting image data into fixed-size patches, flattening and linearly embedding them, then processing them sequentially by a standard transformer encoder.
Vision transformers are also used in image generation and other multimodal AI tasks like image segmentation, object detection, diffusion models, and vision language models, so these models are not limited to NLP. Note that patch embeddings require additional positional encodings, and ViTs often require more data than CNNs to get similar performance, so more resources are needed to run. Multimodal transformers
There are also a few transformers that are designed to handle multiple types of input data (e.g., text and images). These multimodal transformers use dual-stream networks to process visual and textual inputs separately, then fuse the information to understand the relations between the two types.
One of the advantages of AI systems is the ability to select and combine various transformer models based on the task they need to accomplish. For example, a BERT model can work to orchestrate various HR platforms to retrieve the information needed to adjust an employee’s 401(k) plan. However, since some platforms require direct human approval for certain high-value tasks, it can deploy a GPT model to give the employee specific instructions on how to execute the task.
Limitations of Transformer Models
- High computational and memory requirements (especially during training) make them less than accessible to organizations with limited resources
- Long training times, which prohibit rapid experimentation and increase costs
- Many models are complex and operate as “black box” models, with internal decision-making processes that are difficult to interpret
- High sensitivity to the quality and quantity of training data, which is one reason why domain-specific LLMs make these models more robust
- Functional limitations, like positional embeddings, that are required to capture sequence order
- Struggles with tasks that require recursive computation or careful tracking of state (RNNs typically function better in these instances)
The Core Benefits of Transformer Models
Early deep learning models for language relied on mapping word relationships from training data to predict the next word, but were limited by small context windows that reduced output quality. Transformer models fundamentally changed this dynamic, resulting in the following benefits.
These models can be trained or fine-tuned to perform tasks such as answering questions, acting as chatbots, or generating creative content, making them highly versatile for a wide range of applications.
1. Ability to handle large datasets
Because transformer architecture uses parallel computation, it can process long sequences of embeddings in relatively short training and processing times. Many models use billions of parameters to capture a wide range of human language and knowledge, and can also handle very large datasets and model sizes, which is critical for handling complex tasks.
2. Understanding multiple data types
In a similar vein, transformer models can also process and relate information across different data types, integrating these data to more closely mimic human understanding and creativity. An example of this is DALL-E, which combines NLP and computer vision capabilities to convert text-based descriptions into visual art.
3. Deep contextual awareness
The self-attention that provides the core functionality of transformer models represents a major leap forward in deep learning capabilities. Because transformers can model relationships between all embeddings in a sequence, regardless of distance, they can manage long-term dependencies. Embeddings in transformers capture the semantic meaning of tokens, preserving their original context and meaning throughout the encoding process. This gives you deeper context, which improves the model’s reasoning and the quality of its generative output.
4. Domain-specific learning
Transformer models are also capable of implementing techniques like transfer learning and retrieval augmented generation (RAG) that enable the customization of existing models for industry or organization-specific applications. In essence, companies can use foundational models that have been pretrained on large data sets (like a number of open-source models), then fine-tune them on smaller, more specific datasets. After fine-tuning, a post-training phase can further improve transformer performance on specific tasks—like question answering, chatbot behavior, or creative content generation—by training on specialized datasets. This allows you to create highly customised models, domain-specific LLMs, without the resources to build your language models.
How Do Transformer Models Work?
The architecture of a transformer model consists of several software layers that work in tandem to generate the final output. The transformer architecture is made up of both the encoder and decoder components, each composed of multiple layers that process input sequences through self-attention and feed-forward networks.
The architecture is usually an encoder-decoder structure, but many modern models use only the encoder or decoder stack, depending on the task. Here are the layers used in modern transformer architecture.
1. Turning Words into Numbers: Input Embedding & Positional Encoding
AI and ML models are unable to read unprocessed inputs, like raw text. Thus, the first layer of a transformer model converts the text into a format the model can understand, a process known as “tokenization.” These tokens, also called embeddings, each have tens of thousands of “dimensions” which capture the semantic information associated with a given textual value, as well as any information derived from a word’s position in a given sentence (for example, OpenAI’s GPT-3 applies 12,288 dimensions to each token).
When similar texts are embedded, their vector components are similar in the exact same position within the embeddings, which helps preserve word order.
2. Understanding Relationships: The Transformer Block
The next layer of the transformer model is the transformer block itself. As the name suggests, these blocks “transform” the data in such a way that improves the model’s ability to understand them and predict future text based on their values.
Transformer blocks begin with a self-attention described above. In this mechanism, linear layers are used to generate query, key, and value vectors from the input token embeddings. The key and value vectors are important for the attention process as they help the model understand relationships within the data sequence.
The attention weights, computed via softmax, are then combined with the value vectors to produce the output, with the value vector playing a big role in generating meaningful attention outputs. This is important not only to weigh the importance of each word but also to capture highly complex linguistic relationships.
3. Contextualizing Tokens: Encoder Layer
The next layer transforms those tokens into contextualized representations while considering the entire sequence. As an analogy, many data analysts will look for outliers, eliminating them to avoid skewing the results of a given study. In a similar vein, encoder layers stabilize learning models and prevent extreme values from disrupting their overall effectiveness.
4. Predicting the Next Word: Decoder Layer
Next, a decoder layer (or layers) predicts the next token in a sequence, for language, the next word. Each prediction the decoder layer gives is based on a probability analysis of the given text. For example, if a sentence contains the words “Beatles” and “drummer” and ends with the word “Ringo,” the probability of the next word in the sentence being “Starr” is high.
5. Turning Numbers Back into Words: Output Layer
Finally, the output of the decoder layer needs to be converted back from an embedding (which LLMs can understand) into actual text (which humans understand). That’s the job of the output layer. This layer generates output probabilities by passing the classifier’s output through a softmax layer, which converts raw scores into a probability distribution over possible words or classes.
Now what? The model uses these probabilities to predict the most likely next word or sequence. Each key in the output is associated with its corresponding value, so the model can look up and make predictions. Essentially, this layer reverses step 1, and generates the text you see on your screen when you use ChatGPT, Claude, chatbots, Google autocomplete, and more.
Training and Optimization of Transformer Models
Transformer models have changed the game in NLP and sequential data analysis by being able to learn complex patterns and relationships in input sequences. But training these models to their full potential is a complex process that requires planning and the right optimization strategies.
Pre-training and fine-tuning
The journey of a transformer starts with pre-training. In this phase, the model is exposed to a massive corpus of text and learns the general structure and patterns of language. This is often done through self-supervised learning, where the model is asked to predict the next word in a sequence given the context of the previous words. This allows the model to learn the broad language understanding needed for tasks like machine translation or generating the next word in a sentence.
Regularization and preventing overfitting
Given the size and complexity of the transformer architecture, overfitting—where the model memorizes the training data instead of learning to generalize—is a big risk. Regularization techniques are used to combat this. Dropout, for instance, randomly disables some units in the neural network during training, forcing the model to learn more robust features. Weight decay adds a penalty for large weights, so the model has to find simpler, more generalizable solutions.
Scaling up: distributed training and hardware considerations
As transformers get bigger and more complex, training them on a single machine becomes impractical. Distributed training allows the workload to be split across multiple machines and reduces training time, allowing for larger models. Specialized hardware like GPUs and TPUs is essential for training transformer models.
By using distributed training and specialized hardware, organizations can train large transformer models efficiently and unlock new possibilities in NLP, computer vision, and beyond.
In summary, training and optimizing transformer architecture involves pre-training, fine-tuning, advanced optimization techniques, regularization, and scalable AI infrastructure. By harnessing the power of self-attention, multi-head attention, and positional encoding, transformers are setting new benchmarks in NLP and sequential data analysis.
Practical Applications of Transformer Models
Transformer models have a wide range of practical applications, including NLP, computer vision, speech recognition, machine translation, and more. These models undergird chatbots, AI virtual assistants, content generation tools, search engines, Generative AI, and more.
Additionally, transformers are revolutionizing employee experience, especially with regard to employee interactions with HR and IT. Here are just a few examples of these capabilities:
- Generative recommendations for employee development and issue resolution, especially when these transformers are trained on domain-specific LLMs
- Sentiment analysis to identify not only the unstated issues in employee requests, but also to infer urgency and tone
- Real-time chatbots that enable HR and IT teams to reduce manual workload and scale without increasing headcount
- Autonomous self-service portals and AI service desks that enable employees to handle tasks independently
- Smarter AI for ITSM, which can improve resolution times and service reliability
Transformer Models + Agentic AI
Agentic AI and transformer models have a strong connection. In fact, transformer-based LLMs are one of the technological developments that have enabled the rise of Agentic AI, as transformers provide the necessary reasoning, planning, and communication capabilities for autonomous AI agents.
Use of LLMs as cognitive engines
Because transformer-based LLMs are trained on massive datasets, they encode rich semantic and procedural knowledge. This is especially true for domain-specific LLMs, which not only understand but can also generate text that aligns with the nuanced requirements of a given field. This capability enables models to be used not just as text generators, but as separate “brains” that can interpret user goals, generate action plans, orchestrate platforms and tools, and respond to environments like an HR agent updating employee records across all systems.
Autonomy and decision-making
Transformers enable LLMs to process and understand vast amounts of context, enabling them to not only understand and interpret complex instructions but also to observe the environment, reason through options, plan actions, and execute decisions. In essence, transformers redefine what’s possible in automation, decision support, and intelligent workflow management.
Platform and tool orchestration
LLMs that leverage transformers’ flexible input/output capabilities are able to interface with external APIs, databases, and software tools. This means that Agentic AI doesn’t just generate text when prompted with a task. Assuming it has access to the necessary tools, it can orchestrate and execute those AI workflows autonomously, provisioning software and resolving incidents without the need for human intervention.
Multi-agent collaboration
The ability to organize and orchestrate multi-agent systems is a defining feature of Agentic AI. Transformers play a critical role in enabling this capability, namely by supporting the scalable learning needed for decision-making among large groups of agents. For example, role-based multi-agent transformers use sequence modeling to coordinate agent actions, while centralized collaborative graphical transformers can establish structured communication and decision-making protocols among agents.
Final Thoughts on Transformer Models
It is not an overstatement to say that transformer models have revolutionized the field of natural language processing and machine learning. This major leap forward in neural network architecture has enhanced and expanded the capabilities of chatbots, virtual assistants, content generation tools, and more. They have the potential to revolutionize many industries.
Aisera is at the forefront of this revolution. Our Agentic AI platform leverages transformer-based LLMs to autonomously understand, reason, and fulfill user requests. Additionally, our AI agents logically organize themselves by domain, enabling specialized responses based on context and the content of user requests. This not only accelerates response and resolution times, but it does so without the need for significant increases in headcount.
If you’re ready to control your costs, improve the user experience, and get immediate ROI, schedule an AI demo with Aisera today.