
What Are LLM Embeddings?
In short, LLM embeddings are how artificial intelligence translates the world of human language, images, and sound into a numerical language it can understand.
An LLM embedding is that set of coordinates, a list of numbers (a vector) that represents a piece of data’s position on this “meaning map”. By converting text, images, or audio into these numerical vectors, LLMs can do complex tasks like understanding context, measuring similarity, and generating new relevant content. This article will explore how these powerful embeddings are created, why they are important for modern AI, and how they power applications from search engines to generative AI.
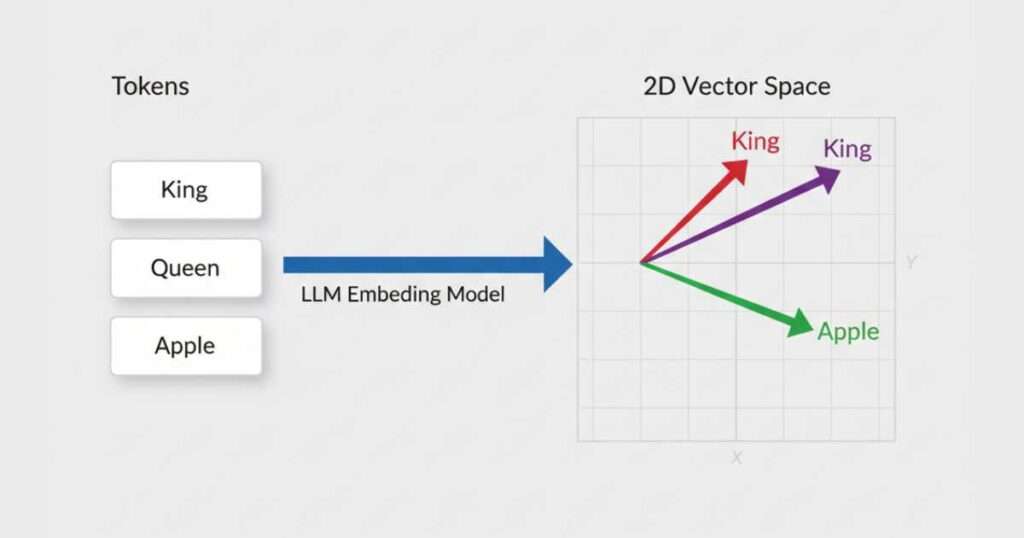
Imagine a giant map where every word or concept has its own set of coordinates. On this map, words with similar meanings like “king” and “queen” are close together. Words that are related but different, like “king” and “palace” are near but not overlapping. And completely unrelated words, like “king” and “dishwasher,” are far apart.
Why are Embeddings a Big Deal for AI?
Embeddings are the semantic foundation of modern AI, connecting the messy human data to the machine’s structured logic. Their importance comes from four key things:
- Context and subtlety: Embeddings let models know that the word “bank” means something different in “river bank” versus “bank account”. They capture meaning beyond just keywords.
- Measuring similarity: By representing everything as numbers, AI can easily calculate how similar two pieces of content are. This is the magic behind better search results, recommendation engines and duplicate detection.
- Efficiency: They compress huge amounts of information into small, dense vectors. This makes it computationally possible to process and learn from billions of data points.
- Generative AI: For an AI to write a paragraph or create an image, it needs to know the relationships between concepts. Embeddings provide the underlying knowledge of those relationships and guide the model to generate coherent and contextually correct output.

How LLM Embeddings Work?
Creating the rich, meaningful embeddings that power modern AI is a two-step process. First, the model must break down raw data into understandable pieces, and second, it must convert those pieces into a universal numerical language of meaning and context.
Step 1: Tokenization – Breaking Data into Building Blocks
Before a Large Language Model can understand a sentence, it first has to learn how to read it. Tokenization is the process of breaking down a sequence of data, like text or an image, into smaller, manageable units called “tokens.”
For text, a token can be a word, a part of a word (like embed and ding), or even a single character or punctuation mark.
For example, the sentence: "The cat sat on the mat." Might be tokenized into: ["The", "cat", "sat", "on", "the", "mat", "."]
This same principle applies to other data types. An image isn’t processed as a whole; instead, it’s divided into a grid of smaller patches, with each patch acting as a token. This method allows the model to analyze data piece by piece, similar to how we read a book word by word instead of trying to absorb the entire page at once. The output of this stage is a simple sequence of tokens, ready for the next, more transformative step.
Step 2: Generating Vector Representations – Assigning Meaning to the Blocks
Once the data is tokenized, the real magic begins. In this step, the LLM converts each token into a sophisticated numerical representation called an embedding or vector.
Think back to the idea of a giant “meaning map”. This is where each token is assigned its specific coordinates. This isn’t just a random number; it’s a high-dimensional vector—a list of hundreds or even thousands of numbers—that captures the token’s semantic essence. This vector is generated by the LLM’s deep neural networks, which have been pre-trained on vast amounts of data.
Crucially, these vectors encode context and relationships. For instance:
- The vector for “king” will be mathematically close to the vector for “queen.”
- The vector for “walking” will be closer to “running” than it is to “studying.”
By converting every token into a vector, the LLM turns a sequence of words into a mathematical object. This object allows the model to understand nuance, grammar and semantic relationships, and now it can do things like answer questions and generate human-like text.
Building Blocks of LLMs
Tokenization, Embeddings, Attention Mechanism, Pre-Training, Transfer-Learning, The strength of Large Language Models (LLMs) is rooted in their structure and the way information flows through their components. The initial step in this process is tokenization, where the input data, whether it’s text, image, video, or image search, is divided into smaller units or tokens.
For instance, when text is used as input, tokens could be a complete phrase, a word, a part of a word, a symbol, or even a single character, depending on the tokenization process. In the sentence “Good Morning, Fred!”, the tokens could be [“Good”, “Morning”, “,”, “Fred”, “!”] based on the tokenization method used. Similarly, when images are used as input, tokens are formed by dividing the original image into pixel groups, each of which can be considered a token.
For example, an image of a landscape could be broken down into tokens representing different sections of the image, such as the sky, trees, and ground. When a tokenizer processes the input data, it encodes it according to a specific scheme and produces vectors that the LLM can comprehend. The encoding scheme is largely dependent on the LLM. Different methods can be used for tokenization. For instance, OpenAI GPT’s Byte-Pair Encoding (BPE) is a widely used tokenizer for text processing. Conversely, Vision Transformer (ViT) and BERT for Image Transformers (BEiT), are popular tokenizers for visual processing.
Types of LLM Embeddings
Unimodal vs Multimodal Embeddings Model
Embeddings can be in Unimodal or Multimodal LLMs. Unimodal embeddings are generated from a single type or dimension of input data, such as text, images, or videos. They capture the semantic context of the data within its modality.
On the other hand, multimodal embedding models are generated from multiple types of input data. They capture the semantic context across different modalities, enabling the model to understand the relationships and interactions between different types of data.
The Evolution: From Static to Contextual Embeddings
Embeddings are a powerful tool in text, image, and video processing, enabling “data objects” with dimensions and similar “meanings” to have similar representations.
Next, we will present cases of the most popular embedding techniques in the context of text data.
Let’s start with basic embedding techniques like one-hot encoding and frequency-based methods such as TF-IDF (Term Frequency-Inverse Document Frequency) and count vectors. In one-hot encoding, each word in the vocabulary is represented as a unique vector in a high-dimensional space, the size and length of which is equal to the vocabulary size.
For instance, if we have a vocabulary of three words: “king”, “queen”, and “building”, the one-hot encoding might look like this: “king”: [1, 0, 0], “queen”: [0, 1, 0], and “building”: [0, 0, 1]. Each word is represented as a binary vector with a “1” at its corresponding index and “0” elsewhere. Even though each word is perfectly distinguishable from others (perpendicular vector represents it in the 3D space), this method fails to capture any semantic or syntactic relationships between words. For example, “king” and “queen”, which are semantically related, are as different as “king” and “building” in this representation.
Exploring Frequency-Based Methods: TF-IDF
TF-IDF, a frequency-based method, represents words based on their frequency in a document compared to their frequency across all documents. While it captures some semantic information, it falls short in capturing syntactic relationships and context.
Let’s assume that in our corpus, “king” and “queen” often appear together in documents about royalty, while “building” appears in a different context. The TF-IDF scores might look something like “king”: 0.8, “queen”: 0.8, and “building”: 0.3. Here, “king” and “queen” have similar TF-IDF scores because they appear frequently in the same documents, while “building” has a lower score because it appears in a different context. However, these scores still don’t capture the semantic relationship between “king” and “queen”, or the syntactic relationships between words in a sentence.
Advanced embedding techniques like Word2Vec, GloVe, and FastText have significantly enhanced word representation. Word2Vec captures semantic and syntactic relationships based on word co-occurrence. GloVe combines co-occurrence information with direct context prediction, while FastText, an extension of Word2Vec, captures the meaning of shorter words and affixes effectively. Let’s consider the case of GloVe and assume that the GloVe embeddings are two-dimensional for simplicity.
The Power of Context in GloVe Embeddings
The embeddings for “king”, “queen”, and “building” might look something like “king”: [1.2, 0.9], “queen”: [1.1, 0.95], and “building”: [0.3, -0.2].
Here, “king” and “queen” have similar embeddings because they often co-occur in the same context, indicating a close semantic relationship. On the other hand, “building” has a different embedding because it appears in a different context and does not co-occur frequently with “king” or “queen”. This shows how GloVe can capture both semantic and syntactic relationships, providing a much richer representation of language compared to TF-IDF.
The latest advancements in embeddings come from transformer models like BERT, BART, XLNet, Longformer, and GPT. These models generate context-aware embeddings, where the representation of a word depends on its context, not just its identity.
Contextualization with Transformer-Based Models
GPT, for instance, infuses its embeddings with positional encodings, ensuring the order of words is preserved. As the input text passes through the transformer layers of GPT, the embeddings evolve, absorbing more context and enriching their representation. By the end, what emerges is a vector representation for each token that is deeply contextualized, reflecting not just the token itself but its relationship with every other token in the sequence.
For example, if we consider two-dimensional embeddings, the embeddings for “king”, “queen”, and “building” might look like this:
“king” in the context of “The king and queen”: [1.2, 0.9], “queen” in the context of “The king and queen”: [1.1, 0.95], and “building” in combination with the context of “The falling building”: [0.3, -0.2].
Here, “king” and “queen” have similar embeddings because they appear in a similar context and are semantically related, while “building” has a different embedding because it appears in a different context and is not related to “king” or “queen”.
This demonstrates how transformer-based models can capture semantic and syntactic relationships between words, providing a much richer representation of language compared to one-hot encoding.
These transformer-based models have set new performance benchmarks on a range of NLP tasks, demonstrating the power of these advanced embedding techniques.
The Role of the Attention Mechanism in LLMs
The attention mechanism is a key part of LLMs. As the LLM model interprets the input data, not all components hold the same importance for comprehending the context or meaning. Some components are more significant than others. This is where the attention mechanism steps in. It allocates varying weights to the embeddings of different tokens, depending on their relevance to the context.
For instance, in the phrase “The captain, against the suggestions of his crew, chose to save the pirate because he was touched by his tale”, the words “captain”, “save”, and “pirate” are key to understanding the overall meaning. The attention mechanism would allocate higher weights to the embeddings of these words.
Enhancing Sequential Models with Attention
In a traditional sequential model, by the time the model processes “save”, the “memory” of the “captain” might have diminished. However, the attention mechanism overcomes this by considering all words simultaneously and allocating weights based on their relevance, irrespective of their position in the phrase. This enables the model to understand that it was the “captain” who decided to “save” the pirate, leading to a more precise representation and understanding of the phrase.
Similarly, in a video, the attention mechanism plays a crucial role in understanding and interpreting the content. A video is a complex combination of numerous frames, each containing multiple elements. These elements could be objects, people, actions, or even subtle changes in lighting and color. Not all these elements are equally important for understanding the context or the narrative of the video.
Attention in Video Interpretation
The attention mechanism, in this case, assigns different weights to the embeddings of different tokens, which could represent various elements within the video frames. For instance, in a video of a bustling cityscape, the attention mechanism might assign higher weights to the tokens representing the main subjects of the video, such as a prominent building, a moving car, or a person interacting with others.
At the same time, it might assign lower weights to the tokens representing the background or less significant elements, like the sky, stationary objects, or the general crowd. In a traditional sequential model, by the time the model processes the later frames of the video, the “memory” of the earlier frames might have faded.
However, the attention mechanism overcomes this by considering all frames at once and assigning weights based on their relevance, regardless of their position in the sequence. This allows the embedding model to understand the continuity and relationship between different parts of the video, such as the movement of the car from one frame to another or the interaction of the person throughout the video.
By doing so, the attention mechanism leads to a more accurate representation and understanding of the video. It enables the model to grasp the narrative of the video, understand the significance of different elements, and recognize the relationships and interactions between them, thereby enhancing the overall interpretation of the video content.
Advanced Concepts: How LLMs Are Trained
Stage 1: Pre-Training on a World of Data
Pre-training and transfer learning are two pivotal stages in the training of Large Language Models (LLMs) for text, image, and video.
In the pre-training phase, the model is trained on a vast corpus of data. This could be a diverse collection of books, websites, image files, videos, and other multimedia content. The goal of this phase is to learn the general patterns and structures of the data.
For text, the model learns to predict the next word in a sentence; for images, it might learn to identify common shapes or colors; and for videos, it could learn to predict the next frame or sequence. This helps the model understand the context and semantics of various elements, whether they are words, visual components, or video sequences. At the end of pre-training, the model has a broad understanding of the data but is not yet specialized in any task.
Fine-Tuning with Transfer Learning
This is where transfer learning comes in. After pre-training, the model is further trained on a smaller, task-specific dataset. This could be a collection of customer service interactions for a chatbot, a set of facial expressions for a facial recognition system, or a series of medical videos for a surgical training tool. The model is fine-tuned on this dataset, which means it adjusts the weights and biases it learned during pre-training based on the new data.
The key idea behind transfer learning is that the knowledge the model gained during pre-training can be “transferred” and adapted to a specific task. The general patterns, values, and structures the model learned during pre-training provide a good starting point, and the model only needs to adjust this knowledge slightly to perform well on the specific task.
This process is much more efficient than training a model from scratch on the task-specific data. It requires less data and computational resources, and it often results in better performance, especially when the task-specific data is limited.
In summary, LLM evaluations indicate that pre-training gives the model a broad understanding of the data, whether it’s text, image, or video, and transfer learning fine-tunes this knowledge for a specific task. This two-stage process is a key reason for the impressive performance on a wide range of tasks across different data types.
What Are LLM Embeddings Used For?
Embeddings are the foundation for Generative AI and Agentic AI across text, audio, image, and video domains. In the text domain, embeddings are used in many Natural Language Processing (NLP) tasks.
For example, in text classification tasks like sentiment analysis or spam detection, embeddings are used to convert the input text into a form the model can process. The model then learns to associate certain patterns in the embeddings with certain classes (e.g., positive or negative sentiment, spam or not spam).
Text Applications
Embeddings are at the heart of most NLP tasks:
- Text Classification: Used in sentiment analysis, spam detection, and intent classification, embeddings help the model recognize semantic patterns associated with labeled outcomes.
- Summarization: Embeddings capture the semantic structure of the input text and allow the model to distill the core meaning into a summary.
- Machine Translation: Embeddings map linguistic relationships across languages and help the model translate text with preserved syntax and meaning.
- Text Generation: In generation tasks like question answering or content completion, embeddings guide the output to be coherent and contextually relevant.
Retrieval-Augmented Generation (RAG) builds on this by combining LLMs with external knowledge retrieval. In RAG, the user input is embedded and matched against a vector store. The retrieved documents are then appended to the prompt, and the LLM generates grounded, accurate, and up-to-date responses, especially useful in enterprise search and AI copilots.
Audio and Speech Applications
- Speech Recognition: Audio is converted into spectrograms and then embedded to capture phonetic and speaker-specific features for transcription.
- Music Classification: Embeddings represent audio features like tempo, pitch and timbre and aid in genre classification and tagging.
- Audio Generation: Used to synthesize or extend sounds based on the embedded representation of previous audio samples.
Video Understanding and Generation
- Object Detection & Action Recognition: Embeddings represent spatial and temporal features across frames and help the model identify objects and classify actions.
- Video Generation: Frame-level embeddings allow the model to generate new sequences consistent with previous visual patterns and maintain temporal coherence.
Storing and Searching Embeddings with Vector Databases
Once an LLM generates an embedding, it needs to be stored in a vector database for fast search. Unlike traditional databases that search for exact matches, vector databases are optimized for fast similarity searches on high-dimensional vectors using HNSW indexing. This powers Retrieval-Augmented Generation (RAG), recommendation engines, and large-scale semantic search.
In fact, Embeddings are vector representations of tokens with context, meaning, relationships, and nuance. Generated by an embedding model, they allow LLMs to understand input data by encoding not just the token itself but its relationships with others.
LLM Embeddings and Tokenization
Technical Insights and Future Directions
It’s important to note that input data varies significantly, and embedding methods must be tailored to the data type. For instance, techniques for text processing differ from those for video processing due to the distinct nature of the information in each. Consequently, different approaches are needed to capture and represent this information effectively.
There is always a tradeoff between precision, memory, and computational cost. Higher precision often demands more memory and computational resources, especially for complex models that capture fine details in data.
Transformer-based models like BERT and GPT generate highly contextualized embeddings but are more resource-intensive than simpler methods like one-hot encoding or TF-IDF. However, their increased precision often justifies the additional cost.
Looking ahead, the field of embeddings is ripe for innovation. As models become more sophisticated, we can expect improvements in precision, efficiency, and the ability to process diverse data types, enabling deeper insights and more complex language processing tasks.
Embedding LLM Model Complexity
Understanding the complexity of embedding techniques for LLMs is crucial for optimizing performance. Different data types, such as text, images, or video, require tailored embedding methods. Balancing precision, memory consumption, and computational cost is key to managing LLM embedding complexity.
However, these precise embeddings come at the cost of increased memory usage and CPU consumption. This challenges the efficiency of LLM models. Simpler techniques like one-hot encoding or TF-IDF are less resource-intensive but lack the depth and context of more sophisticated embeddings. Businesses must weigh the benefits of richer, contextual embeddings against the computational costs, especially in large-scale AI applications where efficiency is critical.
Striking the right balance between LLM embedding complexity, model accuracy, and resource allocation is vital for achieving high performance and cost-efficiency in modern AI systems.
Conclusions
Large Foundation Models (LFMs) and Large Language Models (LLMs) are driving advancements in AI, particularly in natural language processing, image recognition, and audio processing. The strength of these models lies in their structure and the way information flows through their components, including tokenization, embeddings, attention mechanisms, pre-training, and transfer learning.
LLM embeddings are the foundation of modern artificial intelligence. By turning complex data like text, images, and audio into numerical vectors, they provide the framework for machines to understand context, nuance, and relationships.
From simple tokenization of data to the complex, context-aware representations generated by transformer models, embeddings enable a multitude of applications – powering everything from smarter search engines and translation services to advanced generative AI. As this space evolves, we can expect even more precise, efficient, and versatile embeddings to unlock the next generation of intelligent systems.