
What are LLM Agents?
LLM Agents are the next evolution of artificial intelligence, going far beyond your average chatbot. They represent a major leap into the world of Agentic AI systems, using Large Language Models (LLMs) not just as a database of text, but as a reasoning engine to solve problems autonomously.
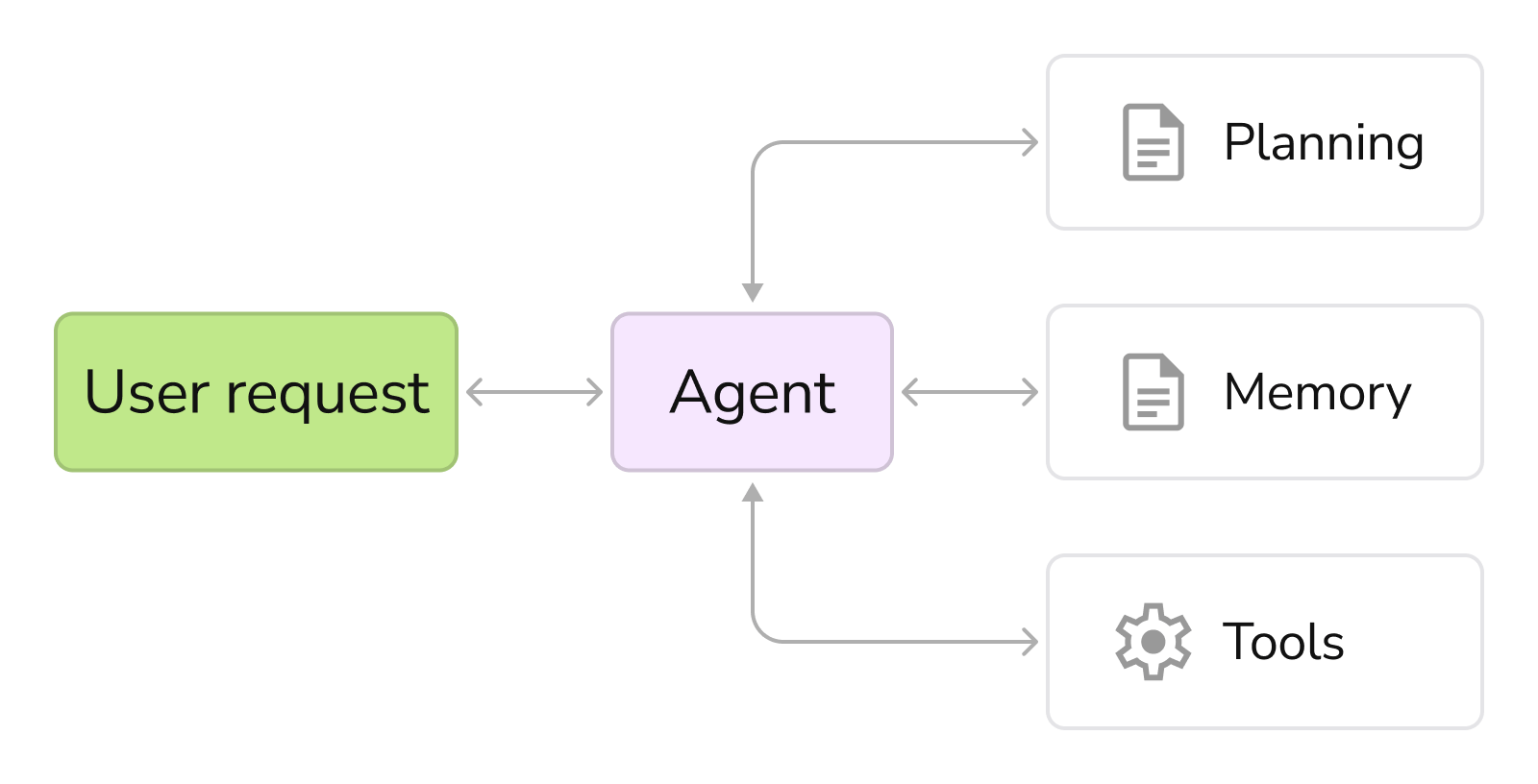
Unlike basic “text-only” models, an LLM agent is an active problem solver. It doesn’t just know things; it can figure out what to do with that knowledge. This agency relies on three core capabilities:
- Planning: The ability to break a goal down into a step-by-step plan.
- Memory: A system to retain context and remember past interactions.
- Tool Use (Function Calling): The power to actively connect to other software, APIs, or data to execute tasks.
In short: A standard LLM is a passive thinker; an LLM agent is an active problem-solver.
Why Enterprises Are Moving From LLMs to Agents
When you have a complex business problem, you can’t just flick a switch and expect a text generator to fix it. Enterprises are realizing that simply hardcoding endless functions into a standard model is slow, brittle, and unscalable.
Standard LLMs often fall short of the task. They are isolated from your live data and can’t take action. LLM Agents change the game. By combining LLM fine-tuning with agentic workflows, you get a system that can:
- Decompose vague queries into manageable sub-tasks.
- Retrieve live data from your specific APIs and databases.
- Synthesize that data to make decisions that actually fit your business context.
LLM Agents vs. Standard LLMs: A Real-World Example
To see how agents really shine, let’s compare how they handle a complex financial question.
The Standard LLM Approach:
- User asks: “What is my current 401(k) balance?”
- Result: The model hallucinates a generic answer or admits, “I don’t have access to your personal info.”
The LLM Agent Approach:
- User asks: “If I boost my investment to the company match limit, how much will I have when I retire?”
- The Agentic Workflow:
- Planning: The agent realizes it needs three specific data points: current balance, match policy, and salary.
- Tool Use: It autonomously “calls” the HR API for the policy and the Finance API for the balance.
- Reasoning: It uses the retrieved numbers to calculate compound interest.
- Response: It delivers a personalized financial forecast, not just a generic definition.
The Architecture: How LLM Agents Work
What enables an LLM agent to go beyond a typical prompt-and-response structure to the point of handling complex queries? How do they remember past conversations, think ahead, and adjust their responses to query context?
To answer these questions, we need to consider LLM-based agents’ overall architecture and individual components. These components form a structured workflow that enables sequential AI reasoning, task breakdowns, and complex data retrieval, allowing the agent to perform advanced operations beyond simple responses.
Large Language Models (LLMs) vs LLM Agents
As the name suggests, a Large Language Model (LLM) is at the heart of the agent. Engineers can use any one of the proprietary or open-source models as the agent’s “brain.” The most effective LLM-based agents, however, are built using domain-specific LLMs that have been fine-tuned for specific industries or use cases, whether through Retrieval Augmented Generation (RAG) or another method.
In these agents, the LLM decides which actions to take by evaluating inputs, reasoning through possible steps, planning actions, and using contextual understanding to autonomously select the most appropriate tools or responses.
Key elements of LLMs include:
- Encoder-decoder structure. LLMs use encoders to convert input text into tokens, which function as “stand-ins” for words and parts of words. They also use decoders to translate outputs from embeddings into text. Not all LLMs use both methods: some use only an encoder (like BERT) while others use only a decoder (like GPT).
- Transformer architecture. LLMs use transformers to prioritize the importance of different words (or, more accurately, tokens) in a sentence and, thus, create more semantically relevant outputs.
- Large-scale pre-training. LLMs are trained on vast datasets containing diverse texts from books, websites, and other sources. This enables the model to identify patterns, learn facts, and perform other activities needed to understand language.
- Fine-tuning. Once pre-training is complete, models are often fine-tuned with domain-specific data, enabling them to handle queries and tasks more effectively within a given sector.
LLM Agent Architecture
LLMs alone do not make an agent. They simply function as the brain of a specific LLM Agent Architecture, along with memory, planning, and tool use.
- Brain: The brain of an LLM agent is the LLM itself. The brain understands language, interprets prompts, and generates responses.
- Memory: Memory enables the LLM agent to remember what’s happened before, and thus operate more autonomously and adaptively. The memory module serves as a core component that stores the agent’s internal logs, including past actions, thoughts, and observations. This enhances the agent’s ability to recall and reason over past experiences, supporting dynamic decision-making and planning.
- Short-Term Memory: Short-term memory maintains the context for the current conversation or task, allowing the LLM agent to track recent prompts, actions, and the immediate environment. Short-term memory is ephemeral and usually limited to the model’s context window.
- Long-Term Memory: Long-term memory, however, enables the agent to recall past interactions and improve its actions and performance over time. It does this by storing information, insights, and user preferences across sessions, often via external databases.
- Hybrid Memory: LLM agents combine short and long-term memory to provide dynamic responses to specific contexts without consuming too many resources.
- Planning: LLM agents use planning to reason through problems, enabling them to break down larger goals into smaller tasks and develop specific plans for tackling each task. LLM agents can also reflect on past actions and adjust future decisions, maintaining their own adaptability and relevance.
- Plan Formulation: First, agents break a complex task into manageable subtasks, allowing the LLM agent to decide which sequence of actions is required to achieve the goal. Agents have multiple options for formulating plans:
- Simple task decomposition involves creating a detailed plan all at once, then following it step by step
- Chain-of-thought (CoT) methods cause agents to tackle subtasks one by one, enabling more flexibility when addressing each step
- Tree-of-thought (ToT) involves breaking down the problem into several steps, generating multiple ideas at each step, and executing the idea with the highest probability of success
- Plan Formulation: First, agents break a complex task into manageable subtasks, allowing the LLM agent to decide which sequence of actions is required to achieve the goal. Agents have multiple options for formulating plans:
With the 401(k) example above, this could include decomposing the query into the following actions: retrieving the company match limit from an HR knowledge base, the requester’s salary and age from employee records, their current account balance and average rate of return from the investment company, etc. As the planning process unfolds, tasks evolve, allowing the agent to adapt its strategy as new information becomes available.
-
- Plan Reflection
The LLM agent can then review and adjust its plan based on new information, feedback, or observed outcomes. This functionality—usually following a methodology known as ReAct or Reflexion—is key to maintaining agent autonomy. In the example above, this could include recognizing—without a prompt—that the employee tends to increase their contribution each year upon receiving a salary increase, impacting the accuracy of the agent’s response.
- Tools used: LLM-based agents can also integrate external tools, APIs, and specialist modules to perform actions that are beyond their native language capabilities. These can include code interpreters (for executing code snippets, allowing the agent to execute code, generate charts, and perform complex programmatic tasks), search engines (for real-time data retrieval), databases and vector stores (for knowledge retrieval), and collaboration and productivity tools (like GitHub, Trello, Google Sheets, and more).
Function calling enables LLM agents to interact with external applications and APIs through predefined functions, often using structured prompts. This allows them to fetch data, execute code, or call external tools seamlessly. The model context protocol provides a framework for standardizing API interactions between LLM applications and external servers, simplifying tool integration and enabling smoother workflows.
Integration with External Tools
An LLM agent’s strengths come from its functionality and use of external tools to enhance and expand its capabilities. This enables an LLM agent to generate more accurate and tailored text, perform real-world tasks, access up-to-date information, and execute complex operations.
LLM agents can overcome their static training data limitations by accessing current and specialized data by tapping into live sources. They can also swap, upgrade, and deploy different tools without retraining their core models.
1. Tool Registration & Schema Definition
First, engineers register all the available tools within the agent’s environment, using structured schemas to describe each tool’s name, function, input parameters, and desired outputs. This explicit schema is critical to enabling the LLM to understand what each tool does and how to use it.
2. Tool Selection & Invocation
When an LLM agent receives a user query, that agent’s brain will analyze the user intent and determine if it needs an external tool to meet that intent. For example, an HR query may require real-time, sensitive data from the user’s employee record to provide a tailored, relevant response.
If needed, the LLM agent will leverage the schema provided in the above registration process, select the appropriate tool, and use it to respond best to the query. Note that unless a given tool has been registered and the schema properly configured, the LLM will struggle to execute this step. In fact, it may even choose the wrong tool for the job, leading to a less-than-desirable outcome.
3. Execution & Response Integration
Once the LLM agent identifies and selects a tool for a given task, it generates a tailored request for that tool and sends it. The tool then executes the task and returns results, which the LLM agent incorporates into future actions.
A straightforward example of this is an API tool, where the LLM agent requests specific data needed to answer the user query—even if the user did not explicitly request that data in the first place. The agent then instructs the API to retrieve them from the necessary source. Again, proper tool schematization and selection are critical for this step to return the desired results.
LLM Agents Applications and Functionality
LLM agents are flexible and adaptable, allowing them to tackle a wide range of applications. Their advanced reasoning capabilities enable them to perform complex problem-solving and decision-making tasks. Let’s walk through a few simple use cases to see how wide their capabilities can be.
-
Work Automation & Workflow Orchestration
Many user queries require more context and data to answer than a straightforward RAG-supported LLM can provide. LLM agents help to automate this information-gathering process, retrieving data from various systems, synthesizing that data, generating reports and responses, and, in many cases, agentic orchestrating and coordinating actions across the tech stack.
-
Robotic Process Automation (RPA) Modernization
Many organizations use rigid, rule-based Robotic Process Automation (RPA) systems for their chatbots and workflows. For example, HR organizations will often use RPA chatbots to automate tasks like interview scheduling, onboarding, leave management, payroll processing, and responding to routing queries.
By leveraging LLM agents, organizations can replace these rigid systems with stronger reasoning skills, the ability to dynamically adapt to edge cases, and domain-specific expertise—which is especially important in sectors like insurance, healthcare, finance, and more. LLM agents utilize sequential reasoning to break down and manage complex, multi-step AI workflows, enabling them to plan, remember context, and connect information across tasks for more accurate and comprehensive automation.
-
Domain-Specific Knowledge & Action
While it’s possible to equip an LLM with a domain-specific RAG system to handle specific queries, the autonomy and adaptability of that setup are limited at best. LLM agents offer a more holistic, sophisticated approach, accessing and synthesizing information from a range of proprietary databases, prioritizing the information most relevant to the query.
For example, LLM agents can use legal databases to retrieve relevant laws, regulations, and court decisions when handling complex legal queries. They can also perform additional research to fill in the gaps and leverage proprietary, user-specific information to achieve the best outcome.
-
Action Execution & Real-World Task Completion
Unlike LLMs, which can only generate text, code, images, and similar outputs, LLM agents can perform real-world actions, thus enabling autonomous follow-through on user queries.
For example, LLM agents can write code to automate workflows or use tools to perform basic math operations, such as multiplication and division, which standard LLMs struggle with. This can be especially useful for repetitive tasks. An LLM agent can also guide a new employee through onboarding, answering questions along the way and freeing up HR employees for more complex and urgent tasks.
-
Autonomous Service Desk
Because they’re built with a sophisticated LLM as their brain, LLM agents are typically more adept at engaging in automated conversational tasks: multi-step customer support, triage tickets, and other tasks that require context-aware, precise responses.
One example is IT Service Management (ITSM), where agents can autonomously interpret user requests, prioritize them, perform necessary system analyses to surface needed context, and either resolve the issue themselves or alert the human IT professional best positioned to help the user.
-
Multi-Agent Systems
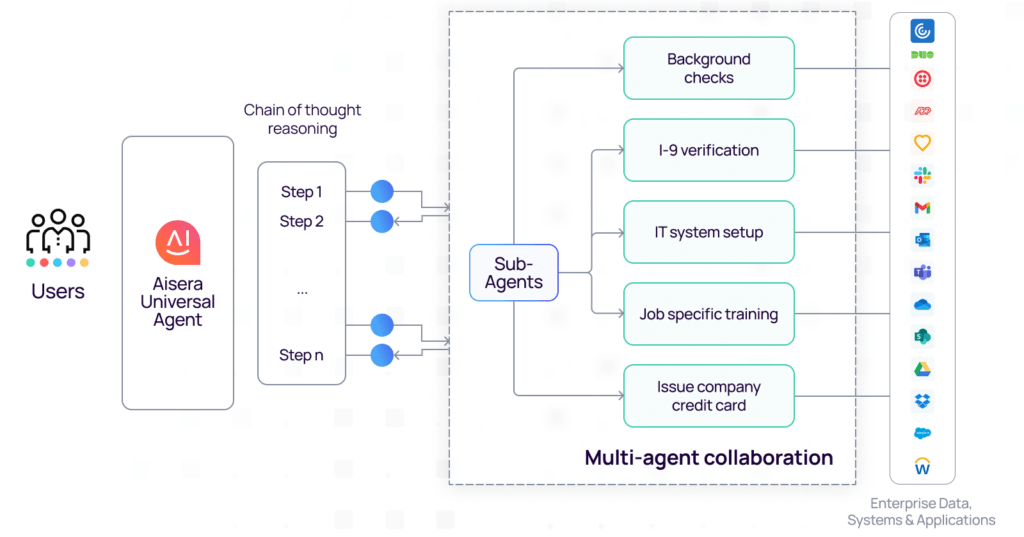
The principle that complex problems require collaboration among specialists isn’t limited to human teams; it’s a fundamental concept in advanced AI, which gives rise to Multi-Agent Systems (MAS). While a single, powerful LLM can be a jack-of-all-trades, a multi-agent approach allows for mastery by division of labor.
Often, a single user query is too broad for one agent to handle optimally. This is where a robust multi-agent framework comes in. This framework is the central nervous system for the collective, responsible for breaking down the main task into smaller sub-tasks, routing each sub-task to the right agent, and synthesizing the individual outputs into a single response.
In a multi-agent system, multiple agents work together, each an expert in its own right. Individual LLM agents can be hyper-specialized in a particular skill area (e.g., summarization, code generation, data analysis, API calls) or a specific domain (e.g., insurance regulations, financial modeling, legal precedent).
Each agent can be fine-tuned or prompted for maximum performance in its narrow field. The entire architecture is an Agentic AI system that orchestrates how these multiple agents work together to solve complex tasks more efficiently.
The image below demonstrates how collaboration works within a multi-agent system.
LLM Agent Frameworks
LLM agents can operate within a range of frameworks. Here are some of the most common.
LangChain
LangChain is a popular modular framework for building context-aware LLM-powered applications and agents. Its key components include an LLM interface, prompt templates, retrieval modules, agents, memory, callbacks, a planning module for enabling complex reasoning and task decomposition, and more. It can easily connect LLMs to APIs, databases, and other tools, making it an excellent hub and repository for advanced AI applications.
LlamaIndex
LlamaIndex is a data framework that’s focused on connecting LLMs to external data sources. Its core components include data connectors, indexing, an advanced retrieval interface, and the ability to integrate with LangChain and other frameworks.
LlamaIndex can also incorporate planning modules, enabling iterative and reflective decision-making by leveraging feedback mechanisms such as environmental observations or user input to refine actions and improve performance. It works particularly well for knowledge management, enterprise search, document Q&A, and any scenario that requires LLMs to reason over large, structured, or unstructured datasets.
Haystack
Haystack is an end-to-end natural language processing (NLP) framework that helps build robust, production-ready NLP and LLM applications. Its key features include pipelines and modular workflows, integration with LLMs, vector stores, databases, and external APIs, built-in RAG support, and evaluation tools. Haystack is particularly useful for enterprise search, document retrieval, and chatbots.
CrewAI & Microsoft AutoGen
While LangChain handles the plumbing, CrewAI and Microsoft AutoGen are leading the charge in Multi-Agent Systems. They allow developers to spin up specific “roles” (e.g., a Researcher agent and a Writer agent) that converse with each other to solve tasks, rather than just executing a linear chain.
LLM Agents Challenges and Risks
While powerful, LLM agents bring significant challenges and risks that must be managed for safe and successful enterprise deployment. The biggest risk is the agent’s LLM brain, where an AI hallucination can go from generating bad text to bad reasoning to bad real-world actions
LLM Security is another big concern; agents are vulnerable to prompt injection attacks where malicious inputs can trick them into using their connected tools to access sensitive data or perform unauthorized actions.
The multistep nature of agentic workflows leads to high operational costs and latency due to cascading LLM calls. Their complex decision-making makes them hard to debug and monitor, which is a big barrier to building production-grade applications.
LLM Agent Evaluation
Although LLM agents use language models as their brains, evaluating their performance is a much more complex, multifaceted process than simple language model assessment. It requires specialized frameworks and metrics to capture the unique capabilities and challenges these models provide.
The most common approach for AI agents is for an LLM or other rubric-based system to evaluate outputs for quality, relevance, and factuality. In edge cases or situations that require more nuanced judgments, humans can be kept in the loop and intervene where needed. Human evaluators are often used to assess the believability and realism of agent behaviors in complex scenarios.
LLM Evaluation Metrics and Best Approach
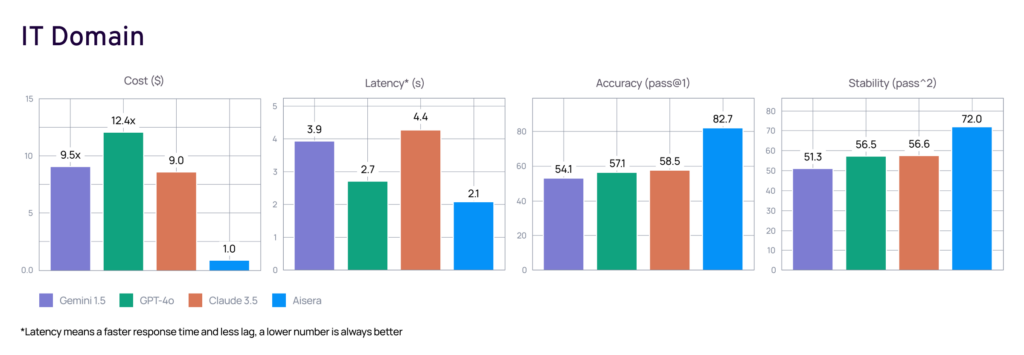
One such approach is the CLASSic framework—an original concept developed by Aisera—that serves as a holistic approach to evaluating enterprise AI agents (including LLM agents) across five dimensions:
- Cost—measuring operational expenses, including API usage, token consumption, and infrastructure overhead
- Latency—assessing end-to-end response times
- Accuracy—evaluating the appropriateness of the workflows the agent selects and executes
- Stability—checking consistency and robustness across diverse inputs, domains, and varying conditions
- Security—assessing resilience against adversarial inputs, prompt injections, and potential data leaks
This framework goes beyond theory. When applied to the IT domain specifically, domain-specific agents operating within the CLASSic framework dramatically outperform agents built on foundation models. They have an industry-leading accuracy of 82.7%, a top stability score of 72%, and an average response time of 2.1 seconds. Learn more about AI agents evaluation and LLM evaluation.
The image below showcases a real-world example of agent evaluation using the CLASSic approach.
How Aisera Improves AI Agents
Aisera helps enterprises leverage Agentic AI to improve efficiency, reduce costs, and empower human agents to spend time on more value-added tasks. In addition to our use of the CLASSic framework for agent evaluation (see above), we improve our agents in the following ways:
- Domain-specific LLMs. All our LLM models and agents are fine-tuned and grounded in industry- or organization-specific data. This enables our AI agents (including LLM agents) to outperform their generic counterparts in terms of accuracy, relevance, and real-world value.
- Comprehensive evaluation and benchmarking. Using the CLASSic framework mentioned above, we curate diverse benchmark tasks and datasets across a wide range of agent capabilities, employing both automated metrics and human evaluation to guide continuous improvement and inform future model selection and deployment.
- Industry leadership and open standards. Our frameworks and benchmarking studies have been recognized at leading AI/ML conferences (e.g., the ICLR Workshop on Trustworthy LLMs). By open-sourcing this benchmarking framework, we hope to drive innovation and standardization across the AI community.
Future of LLM Agents: What’s Next?
LLM agents’ future is about rapid evolution from single-task executors to more autonomous and integrated digital partners. A big trend is multi-modal agents that can see and act on not just text but also visual information like screenshots and GUIs to operate software just like a human.
We’ll also see agent societies where instead of one big monolithic agent, complex tasks are handled by a team of smaller, more cost-effective expert agents (e.g., a “researcher,” a “coder,” or a “communicator”) managed by a central orchestrator.
Perhaps most exciting is the pursuit of self-improving agents that can learn from their mistakes, refine their plans, and even suggest improvements to their tools, creating a feedback loop of increasing capability. This will ultimately transform agents from reactive tools to proactive partners that can anticipate needs and automate complex workflows across our digital lives.
Final thoughts
LLM agents are critical components of Agentic AI workflows, enabling companies to automate solutions to increasingly complex user problems, especially in areas like employee engagement, HR, IT, and more. By combining the sophistication of modern LLMs with agentic autonomy and domain-specific expertise, Aisera’s LLM agents outperform their industry counterparts – all while maintaining rigorous compliance with security and regulatory standards.
To learn more about the Aisera AI Agent Platform, schedule a demo with our team today.